Posts Tagged ‘open data’
Das Kölner OK Lab: einfach mal in der Wikipedia sitzen, Bier trinken und programmieren
So, erst mal vorsichtig den Staub hier wegpusten…
Über ganz Deutschland verteilt gibt es OK Labs, regionale Gruppen von ProgrammiererInnen, DesignerInnen oder interessierten BürgerInnen, die sich für offene Daten und ihre Anwendungsmöglichkeiten interessieren.
Die Kölner Gruppe beschreibt sich so:
Das Kölner OK Lab ist eine regionale Gruppe von Designern, Entwicklerinnen, Journalisten und Anderen, die sich regelmäßig treffen, um an nützlichen Anwendungen rund um Offene Daten zu arbeiten.
Unser Treffen findet alle zwei Wochen statt. Schaut einfach in unserer Meetup Gruppe vorbei!
Wir entwickeln Anwendungen, die Kölner Spielplätze oder Denkmäler auf Karten zeigen, für Tiere aus Kölner Tierheimen per Twitter ein Zuhause suchen oder in 3D zeigen, wie viele junge Menschen wo in Köln wohnen.
Andere Projekte der Gruppe sind z.B.: „OpenAir Cologne“, ein Netzwerk selbstentwickelter Sensoren um die Stickstoffdioxid Belastung in der Stadt messen zu können, oder „KVB Fahrräder“, eine Webseite um die (errechnete) Nutzung der Fahrräder zu visualisieren.
Viele der Anwendungen nutzen auch Datensätze die über das Portal „Offene Daten Köln“ zur Verfügung gestellt werden. Für meine Projekte habe ich etwa folgende Quellen benutzt:
- Aktueller Pegelstand des Rheins, bereitgestellt von den Stadtentwässerungsbetrieben Köln
Mein Twitterbot @koelnpegelbot nutzt diese Schnittstelle um über den aktuellen Wasserstand zu informieren. Der Bot kredenzt dazu noch eine kölsche Lebensweisheit oder rechnet den Pegelstand lokalspezifisch in Kölschstangen um. (GitHub Repository)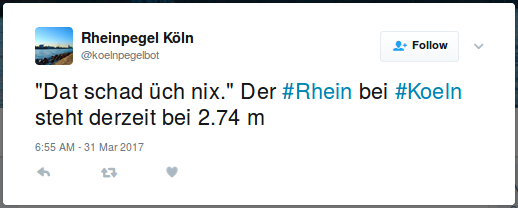
Der Pegelbot twittert den Wasserstand des Rheins
- Diversity Kalender Köln
Dieser Kalender beinhaltet die Fest- und Feiertage der großen Religionsgemeinschaften sowie weltliche Fest- und Feiertage. Leider wurden die Daten nur als CSV publiziert, daher habe ich ein kleines Skript geschrieben, dass die Daten in eine ICS-Datei konvertiert, damit der Kalender einfach in gängige Software importiert werden kann. (GitHub Repository)
Um etwas Erfahrung mit der Programmiersprache Go und Mikroservice-Architekturen zu sammeln habe ich auch einen kleinen Webservice geschrieben, der die Feiertagsdaten nach Abfrage als JSON liefert. (GitHub Repository)
Auch das hat wieder zu einem neuen Twitterbot geführt: Der @feiertagbot informiert über die Feiertage und versucht auch über die Wikipedia mehr Informationen dazu zu liefern.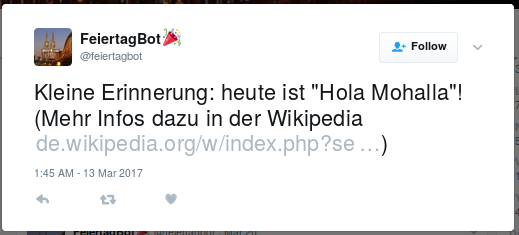
Ein TwitterBot mit Partyhütchen
Eine Besonderheit der OK Lab Treffen in Köln ist auch der Ort: Man trifft sich im „Lokal K“:
Das Lokal K wurde als Pilotprojekt für einen regionalen Stützpunkt von einer Gruppe in Köln und Umgebung ansässiger Wikipedianer gemeinsam mit dem Wikimedia Deutschland e. V. (WMDE) eingerichtet. Es wurde durch WMDE angemietet und laufende Kosten sowie weitere Kosten zur Einrichtung und zum Betrieb werden von WMDE getragen […].
Man sitzt also sozusagen physisch in der Wikipedia…
#bibtag14 – Tag 3: Mit MC Hammer BibliothekarInnen irritieren?
So mein Vortrag ist vorbei, ab jetzt wird’s entspannt …
Begonnen hat der Tag für mich mit der Session „Neue Formen der Erschließung“. Ich hatte etwas befürchtet, dass ich mit dem Twitter-Humor meines Bots die Leute verschrecke, aber die Resonanz war eigentlich ganz gut:
Hier noch die Folien:
Auch die anderen Vorträge in der Session fand ich spannend. Viele Beispiele, wie man Mehrwert durch die Verknüpfung von freien Datensammlungen schaffen kann. Endlich gibt es Anwendungsfälle, mit denen man das Potential von Linked Open Data schön zeigen kann.
Schöne Projekte mit viel GLAM!
Im Moment gibt es wieder spannende Initiativen aus dem GLAM-Bereich:
Letztes Wochenende begann in Berlin ein „Kultur-Hackathon“:
Nach dem Motto „Let them play with your toys!“ (Jo Pugh, National Archives UK) wollen wir im Rahmen von Coding da Vinci ergründen, was passiert, wenn Kulturinstitutionen mit der Entwickler-, Designer- und Gamescommunity ins Gespräch kommen und in kreativer Art und Weise das digitale Kulturerbe nutzbar machen.
Auf Basis von offenen Kulturdaten entstehen prototypische Anwendungen in einem gemeinsamen Dialog mit Kulturinstitutionen und Teilnehmer/innen aus ganz Deutschland.
Eine großartige Idee, um einmal zu schauen, was man denn mit unseren tollen bibliothekarischen Daten so alles anstellen kann.
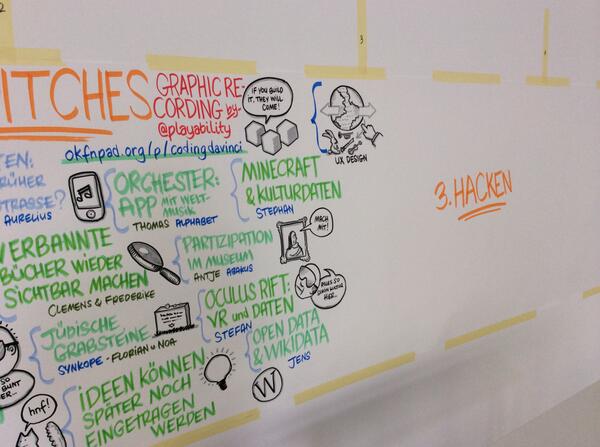
Hübsche Art der Dokumentation mit Sketchnotes
Erste Projektideen (von der Weltkriegsdokumentation bis zum Vogelstimmenwecker) kann man sich bereits ansehen, ich bin gespannt, was in den nächsten 10 Wochen noch so alles entstehen wird.
Tim Sherratt hatte ich ja im Zusammenhang mit dem TroveNewsBot schon einmal erwähnt. Nun gibt es ein neues Projekt von ihm:
Faces offer an instant connection to history, reminding us that the past is full of people. People like us, but different. People with their own lives and stories. People we might only know through a picture, a few documentary fragments, or a newspaper article.
On this site I’m exploring whether faces can provide a way to explore more than 120 million newspaper articles available on Trove.

„Eyes on the past“
Mir gefällt ja dieser verspielte Ansatz der digitalen Sammlung als „Wunderkammer“ sehr gut. Auf Twitter wurde das als „a poetic way to search library catalogues“ bezeichnet und in der Tat ist „Eyes on the past“ wohl die maximale Distanz zur Boole’schen OPAC-Suchmaske.
(Das Projekt läuft derzeit auf einem Testserver, falls der Link irgendwann nicht mehr funktioniert, findet man vielleicht auf der Homepage des Entwicklers noch mehr Informationen dazu.)
Mit offenen lobid-Daten raten!
Für ein kleines Datenanalyseprojekt brauche ich die Gender-Verteilung einer Namensliste. Das manuelle Durcharbeiten und Anlegen einer Strichliste ist relativ öde, daher habe ich nach einer automatisierten Lösung gesucht und einen schönen Anwendungsfall für offene Daten gefunden…
Das hbz bietet ja mit lobid.org eine API für die Abfrage der „Gemeinsamen Normdatei“ an. In der GND-Ontologie ist ein Gender-Eintrag definiert und manchmal auch vergeben.
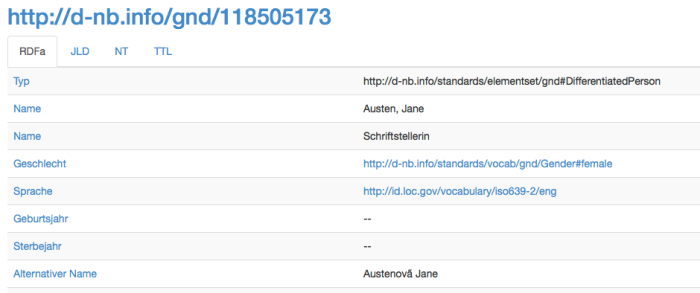
Jane Austen in der GND
In weiterer Folge habe ich jetzt ein kleines Perl-Modul geschrieben, das die GND Personendaten durchsucht und für die ersten 100 Treffer die Gender-Einträge analysiert. Daraus wird dann eine statistische Präferenz abgeleitet:
> perl guess.pl Peter
'Peter' is probably 'male'
Here's the statistics data that I've used: $VAR1 = {
'GenderRatio' => {
'Female' => '8.33333333333333',
'Male' => '91.6666666666667'
},
'GenderDistribution' => {
'female' => 2,
'male' => 22,
'notKnown' => 43
},
'GenderCount' => 67,
'TotalCount' => 100
};
> perl guess.pl Sarah
'Sarah' is probably 'female'
Here's the statistics data that I've used: $VAR1 = {
'GenderRatio' => {
'Female' => '95.4545454545455',
'Male' => '4.54545454545455'
},
'GenderDistribution' => {
'female' => 21,
'male' => 1,
'notKnown' => 41
},
'GenderCount' => 63,
'TotalCount' => 100
};
Aus den Statistikdaten wird klar, wie schlecht die Datenlage eigentlich ist, in den meisten Fällen wurde in der GND notKnown vergeben. Trotzdem ist das Ergebnis für „Standardnamen“ relativ eindeutig.
Schwieriger wird es für Vornamen, die sowohl weiblich als auch männlich besetzt sind (Uli, Kim, Andrea, etc..).
Bei „Andrea“ schlägt auch noch die automatische Trunkierung zu und der Name wird zu 92 % als männlich klassifiziert.
Trotz dieser Schwächen ist dieses Verfahren aber immer noch eine pragmatische Lösung und ein schönes Beispiel für die (Nach-)Nutzung bibliothekarischer Arbeit.
Wer das Modul verwenden will, oder Bugreports oder Verbesserungsvorschläge hat: hier geht’s zum GitHub-Repository!
Jede Menge Nobelpreise für den @EuropeanaBot
Nun gut, der EuropeanaBot findet jetzt österreichische Orte und Katzenbilder. Das ist ja alles ganz nett, aber doch ein sehr eingeschränktes Themenspektrum.
Also war ich auf der Suche nach einem weiteren offenen Datenset, mit dem sich in der Europeana interessante Bilder finden lassen. Personendaten sind da relativ naheliegend (es gibt etwa jede Menge Bilder von Schauspielerinnen oder Politikern). Eine ziemlich interessante Menge an potentiellen Suchtermen ist aber auch die Liste der NobelpreisträgerInnen, die dankenswerterweise als offene Daten im JSON- oder CSV-Format zur Verfügung gestellt wird.
Insgesamt ist das eine Liste mit 864 Personennamen und wenn man damit die Europeana füttert, bekommt man so schöne Ergebnisse, wie etwa ein Bild von Konrad Lorenz auf dem Motorrad:
Die Liste wird vom Bot wieder durchgemischt und Ergebnisse werden mit verschiedenen Texten getwittert. Die Tweets sind also insgesamt wieder etwas interessanter geworden und das Verhältnis der einzelnen Themenbereiche hat sich damit zu 10 % Katzenbilder, 30 % Ortsbilder, 50 % NobelpreisträgerInnen und 10 % Sonstiges verschoben.
Die genauen Änderungen kann man wieder auf GitHub verfolgen.
#sigint Tag 2: ein Pull-Request aufs Grundgesetz
Der letzte Vortrag für mich an diesem Abend war: „DocPatch: Entdecke unsere Verfassung“. Der Chaospott hat da dem deutschen Grundgesetz ein besonderes Geburtstagsgeschenk zum 64. gemacht: eine Publikation als offene, versionierte Plattform, mit der sich sämtliche Änderungsanträge von 1949 bis heute nachvollziehen lassen. Entweder als Diff oder schön visualisiert als Zeitleiste.
Quellen waren dabei die Bundesgesetzblätter und diverse Publikationen des wissenschaftlichen Dienst des Bundestags und natürlich musste viel Arbeit investiert werden, um aus den Dokumenten eine maschinenlesbare Variante zu erstellen.
Diese Rohdaten liegen jetzt auch im Markdown-Format in einem GitHub-Repository (schon wieder ein ungewöhnlicher GitHub-Anwendungsfall..) und können somit von anderen nachgenutzt werden.
Auch die Software, die für dieses Projekt entwickelt wurde – „DocPatch“ kann frei nachgenutzt werden.
Bei den restlichen Gesetzen auf Bundesebene gibt es übrigens auch ein Open-Data Projekt: BundesGit.
Offene Katalogdaten in freier Wildbahn gesichtet!
Eine der häufigsten Rückfragen beim Thema „(Linked) Open Data“ im Bibliotheksbereich ist ja immer die Frage: „Was bringt die Freigabe der Katalogdaten eigentlich?“
Es ist immer die Rede von tollen, neuen Anwendungen die mit den Daten ermöglicht werden, an konkreten Beispielen fehlt es aber oft.
Von daher war ich positiv überrascht, als ich in der Wikipedia ISBN-Suche einen neuen Dienst entdeckt habe: isbn2toc.
Hier hat offensichtlich wer die Links zu den Inhaltsverzeichnissen aus den Katalogdaten extrahiert und bietet eine Suche über die ISBN an.

isbn2toc Ergebnisseite
Die Ergebnisseite ist zwar mehr funktional als hübsch, der Dienst funktioniert aber.
Also alles in allem, ein schöner kleinen Nischendienst, der etwas Sinnvolles mit Bibliotheksdaten anstellt…


